貝氏分類器為一基於機率的分類器,並假設各個特徵間相互獨立。要了解貝氏分類器,我們要先來認識赫赫有名的「貝氏定理」。
貝氏定理 Bayes’ Theorem
貝氏定理描述在一些已知的條件下,某件事情發生的機率。比方說,如果我們已經知道房價與房子的區域位置有關,那麼使用貝氏定理則可以透過得知房子的位置,更準確地推估房子的價格。
上式意思為若我們想要得知在已知B事件發生下,A事件發生的機率為何?
我們可以這樣理解。 首先,在事件B發生之前,我們對事件A會有一個基本的機率判斷,因此我們稱$P(A)$為”事前機率”。 而在事件B發生之後,我們會對事件A發生的機率重新評估,因此我們稱$P(A|B)$為事件A的事後機率。 另一方面,在事件A發生之前,我們也會對事件B有一個基本的機率判斷,我們稱$P(B)$為”事前機率”。 同樣的,在事件A發生之後,我們亦會對事件B的發生機率從新評估,因此我們稱$P(B|A)$為事件B的事後機率。
綜合以上,在機去學習裡面我們可以把此方程式看成:
在貝氏學習裡,我們想要得到的是,究竟是怎麼樣的假設,比較符合我們觀察到的資料,也就是要找到一個讓$P(假設|資料)$最高的”假設”。
很顯然的,$P(假設|資料)$會隨著$P(資料|假設)$及$P(假設)$上升而上升,但會因$P(資料)$的上升而下降。
到了這邊,可能還是覺得有點似懂非懂,讓我們一起來看個小例子,可能會更為明白!
如果有一天你出差回家,在家裡發現了不是自己的內衣褲,究竟伴侶欺騙你的機率有多少?
讓我們一起對照著上述公式。在這個例子中,資料的部分為”發現家裡有非自己內衣褲的事實”,而假設的部分則為”伴侶欺騙了自己”。(另一個假設則是”伴侶沒有欺騙自己”,我們最後可以用貝氏定理來推估哪一個假設的機率高,在此先只關注其一假設) 很顯然的,我們的目標算出$P(假設|資料)$指的就是當我們回家發現家裡有非自己內衣褲的事實,在這樣的情況下,伴侶欺騙我們的機率有多少?
要得到這個機率,我們需要三個機率,分別為$P(資料|假設)$、$P(假設)$與$P(資料)$。在這裡,$P(資料|假設)$指的就是”在伴侶欺騙我們的情況下,我們發現非自己內衣褲在家的機率有多少? 我們稱此機率為在假設情況下得到此資料的後驗機率。” $P(假設)$指的是,不論任何情況(尚無資料的情況下),伴侶欺騙我們的機率有多少?我們稱此機率為假設的先驗機率。 而$P(資料)$指的是, 不論任何情況(無論伴侶有無欺騙),我發在家發現非自己內衣褲的機率有多少,我們稱此為資料的先驗機率。綜合以上,我們很快就可以算出當我們回家發現非自己內衣褲的同時,伴侶欺騙我們的機率,也就是$P(假設|資料)$。因篇幅關係,詳細計算過程歡迎參考影片。
有意思的是,當我們出差回來,”再次”在家中發現非自己內衣褲時,伴侶欺騙我們的機率還會跟原本一樣嗎? 相信依照大家的直覺,想當然耳被欺騙的機率肯定會飆高,而在貝氏定理中呢?
在第一次事件發生時,我們已經得知了$P(假設|資料)$也就是在我們發現非自己的內衣褲而伴侶欺騙我們的機率。因此,回到貝氏定理中,因這已經是第二次發現這樣的事情,有了先前的經驗,$P(假設)$亦即伴侶欺騙我們的機率,會跟著更新為$P(假設|資料)$,導致我們最後算出的機率也會有所不同! 這就是所謂的貝氏學習!
貝氏學習 Bayesian Learning
了解了貝氏定理的原理之後,接下來,我們要探討的是貝氏分類器究竟是如何運作的呢?
首先,我們知道在貝氏分類器底下,我們的目標(target)就是要找到一個”假設”讓$P(假設|資料)$為最大。當$P(假設|資料)$為最大時,我們就會將這個樣本分類到這個假設。以上例來說,如果我們算出$P(伴侶欺騙|回家發現非自己的內衣褲)=0.3$,$P(伴侶誠實|回家發現非自己的內衣褲)=0.7$,則貝氏分類器會將結果分類到”伴侶誠實”這個假上裡面,因為$P(伴侶誠實|回家發現非自己的內衣褲)=0.7>$ $P(伴侶欺騙|回家發現非自己內衣褲)=0.3$。
寫成數學式子,透過貝氏定理我們可以得到:
單純貝氏分類器 Naive Bayes Classifier
單純貝氏分類器為貝氏定理的實際應用,模型中假設所有的特徵都是獨立的。透過貝氏定理的計算,我們可以知道在已知的資料下哪個目標的發生機率最大,由此去做分類。在資料量夠多的情況下,單純貝氏分類器是一個相當好用的模型,簡單且有效,又不容易產生過度擬和。
承前所述,我們已經知道在貝氏分類器底下,我們的目標就是要找到給定資料後事件發生機率最高的假設$P(假設|資料)$,翻譯成在機器學習裡我們熟悉的語言,就是要找到給定特徵下事件發生機率最高的目標$P(y_i|\mathbf X_i,D)$,其中$\mathbf X_i=<x_1,x_2,x_3,…,x_n>$,代表著各個特徵。$y_i$則代表著所有結果中的其中一種結果,而發生機率最高的$P(y_i|\mathbf X_i,D)$裡的$y_i$,我們稱之為$y^*$,也就是分類器對該樣本最後判定的類別。
以數學式子表達:
而藉由貝氏定理,我們得到
很顯然的,我們只要有$P(y_i)$及$P(x_1,x_2,…,x_n|y_i)$,就可以建模了!而很幸運的,這些資料都可以從訓練集的樣本計算而來! 其中,因假設各個特徵相互獨立,所以
最終,式子會變成
讓我們一起看個小例子可能更容易理解! 早上起床,看看窗外的天氣,今天適合出門打網球嗎? 我們蒐集了過去兩周天氣的資料(如下表),該應用單純貝式分類器來幫我們預測今天是否適合出門打網球呢?
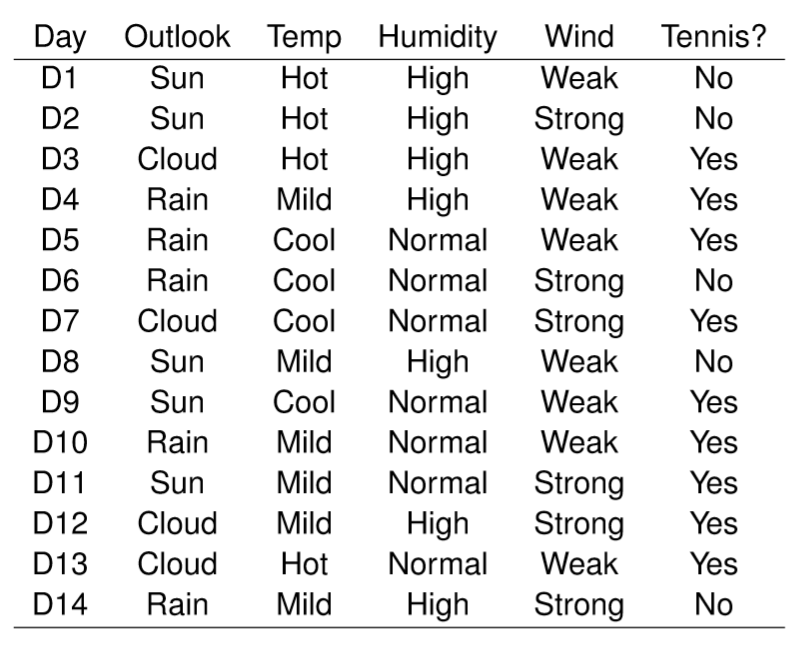
從上表我們可以清楚的看到,天氣特徵的部分包含了Outlook(晴天, 陰天或雨天), Temp(溫度高,中或低), Humidity(濕度高或正常), Wind(風力強或弱)共4個特徵,而目標的部分則是Tennis?(是否適合出門打網球)。
我們觀察到今天的天氣特徵$\mathbf X =<Outlook=Sun, Temp=Cool, Humidity=High, Wind=Strong>$,適合出門打網球嗎?
很顯然的,我們透過計算在這樣情況下的$P(Tennis?=Yes)$以及$P(Tennis?=No)$,然後看哪一個機率高答案也跟著呼之欲出了!
根據貝氏定理,我們知道我們要找的最終結果是
很清楚的,只要從樣本中分別算出上式出現的這些機率,我們就可以得到答案了! 首先,從我們的14天樣本中可以得知,其中有9天是適合打網球的,而有5天是不適合打網球的。因此適合打網球的機率與不適合打網球的機率分別為:
接下來,我們觀察到在適合打網球的9天裡,有3天風速是很強的。而在不適合打網球的5天裡,也有3天風力是很強的,因此我們分別推算出在適合打網球的時候風力很強的機率,以及在不適合打球的時候風力很強的機率,詳列如下:
依此類推,我們可以依照這樣的方式觀察在適合打球的日子裡,分別推估$P(Sunny|Yes), P(Cool|Yes), P(High|Yes)$,以及觀察在不適合打球的日子裡, 分別推估$P(Sunny|No), P(Cool|No), P(High|No)$。 (詳細過程有需要可參考影片)
有了所有原料後,我們帶入原式可得
把算出的結果全部相乘,我們可以得到
很顯然的,適合打網球的機率為0.0053小於不適合打網球的機率0.0206,因此最終單純貝氏分類器會判定答案為不適合出門打網球。
最後,我們可以將上市算出的機率標準化得到真正的機率:
因此,最後我們不僅可以從單純貝氏分類器得到預測結果外,更可以知道預期的程度。
單純貝氏分類器可能會遇到的一些問題
當樣本數數目夠多的時候,採用貝氏分類器是一個很棒的想法,因為從眾多樣本算出的機率不容易有偏差,可以有效避免過度擬和的問題,這是貝氏分類器很大的一個優勢!
然而,在單純貝氏分類器裡面,透過上述的計算過程,我們可以發現,當特徵數很多的時候,相乘之下所算出的機率值會非常小,造成在程式運算上面容易因為儲存問題而造成偏誤,這時我們就可以透過取log的方式來避免這樣的問題。
另一方面,若是樣本不大,當我們在計算條件機率時,很有可能因為樣本裡很少發生這樣的事件,產生偏誤,而導致這個機率趨近於0。以上面的例子來說,假設在我們的樣本裡面算出的$P(Strong|Yes)$是一個趨近於0的數值,那最終的結果就會變成即使其他條件機率算出來是高的,最後相乘之後得到的結果還是會很小。這時,我們可以透過equivalent sample size來解決這個問題,也就是分子分母分別加上一個常數乘積與常數。舉例來說:
在這裡,$n$指的是在我們樣本裡面適合打網球的次數,$n_c$則是指樣本裡面當適合打網球時風力很強的次數。很明顯的,當$n_c$很小的時候,就會導致$P(Wind=Strong|Tennis?=Yes)$趨近於0。然而,這很有可能是因為樣本太小而造成的偏誤。因此,我們可以透過equivalent sample size來解決這個問題,也就是:
其中,m是一個常數,也就是我們所稱的equivalent sample size。而$p$則為先驗機率。一般來說,我們會先讓$p=\frac{1}{k}$,以這個例子來說,風強度有強弱兩種,那麼$k$就等於2,所以$p=\frac{1}{2}$。當然,這些都有很多不同的估計方式,最重要的是選到適合自己資料的方式。
高斯貝氏分類器( GaussianNB)
到了這邊,細心的朋友可能會發現到,在單純貝氏分類器裡面的例子裡面,我們所給定的特徵都是離散的類別變數。如果今天我們的特徵是連續的數值,該怎麼辦呢? 這時候,高斯貝氏分類器就派上用場了!
在單純貝氏分類器中,我們所得到的結果其實都來自於樣本裡的機率,因此可以把式子寫成:
而在連續變數的特徵中,我們可以藉由假設變數為常態分配的情況下,以樣本的資料的標準差及變異數來計算機率,算式如下:
同樣的,在貝氏分類器中,因為我們假設所有的特徵都是相互獨立的,因此在這裡我們可以透過常態分配來計算相對應的機率,並將它們相乘起來。另外,還有很多種分配的假設都可以作為應用,比方說當資料為二元值時,我們也可以採用伯努力(BernouliNB)分類器。而在離散資料方面,我們也可以採用多項式(MultinomialNB)分類器等等。
結語
今天,我們認識了貝氏分類器,並透過範例理解了模型背後的原理。另外,我們也學會了該怎麼處理單純貝氏分類器過度擬合的問題。除此之外,我們也知道在不同的資料特徵下分別可以選擇採用那些適合的貝氏分類器。
下個單元,我們將一起在Python裡進行貝氏分類器的實作!
參考資料
Machine Learning — A Probabilistic Perspective, Kevin P. Murphy Probabilistic Models, Simon